

It has been a while since I’ve written a new blog post. That’s not because I ran out of things to write about. Over the past year and a half, I’ve been busy working on a number of other projects, and blogging fell down the priority list.
But there’s another reason.
Most of my previous posts were born out of frustration. I would run into a particularly difficult problem—usually involving Windows, PowerShell, or Active Directory—and after spending hours or days digging through documentation, experimenting, and reverse-engineering the issue, I would eventually figure out the solution. At that point, I’d write it up so the next person didn’t have to suffer through the same process.
That dynamic has changed dramatically.
With the current state of AI, many of the problems that used to require hours of research and experimentation can now be solved in minutes. The friction that used to generate blog posts isn’t there anymore.
But one of the major downsides to AI streamlining and minimizing friction with technology has been the utter devastation to the cybersecurity capture-the-flag competition. And I want to tell you a bit about my experience and how, unfortunately, my team and I won this year’s BSides Seattle CTF competition.
The B-Sides Seattle 2026 CTF
I recently competed in the B-Sides Seattle 2026 Capture the Flag competition. The event runs for two full days and follows an attack-defense format: each team operates their own instance of multiple vulnerable services while simultaneously attacking the same services hosted by other teams.
Last year, during the 2025 competition, my team of three took third place. Even then we came to a realization: it was no longer realistic to compete in a CTF without using AI.
At the time we relied heavily on ChatGPT for things like:
- Vulnerability analysis
- Script generation
- Reconnaissance assistance
- Patch creation
The speed increase was significant. AI helped us move through reconnaissance, vulnerability identification, exploitation, and defensive patching much faster than we could manually.
But that was still what I would call AI as an assistant.
This year was something entirely different.
From AI Assistants to AI Agents
Over the past year there has been a lot of discussion around AI agents—systems capable of performing tasks autonomously rather than simply responding to prompts. Most early implementations felt immature. Interesting, but not yet capable of reliably executing complex workflows.

For this year’s competition, we built something closer to a real agent system. Instead of using a single model interactively, we orchestrated a set of agents with direct access to our Kali attack infrastructure. Each agent could analyze systems, generate code, execute exploits, and adapt its strategy based on results.
The architecture was simple but extremely powerful:
- One dedicated AI agent per service box
- An orchestration agent coordinating them
- All agents running simultaneously
At any given time we had more than ten agents operating in parallel, each focusing entirely on a single target system.
Each agent was responsible for the full lifecycle of its assigned box:
- Vulnerability discovery
- Exploit development
- Exploit execution
- Patching our own system
- Exploiting competitor systems
- Submitting flags
Before anything else, the first thing we gave the orchestrating agent was the rules of the competition. It was critical that the system stayed within the allowed boundaries. Services had to remain operational, and attacks had to comply with the event rules.
Everything we did during the competition was fully within those constraints.
What happened next was… unsettling.
Three Hours…
Within the first three hours of the competition we had compromised nearly every service box.
Out of ten systems, nine were fully exploited and generating flags. Only one remained unsolved. That final system required a long exploit chain involving a stored cross-site scripting vulnerability that had to be combined with multiple backend processing flaws.
Our primary agent (running Claude) wasn’t able to fully construct the chain. So we tried something different. First, we had Claude produce a dossier describing everything it understood about the vulnerability and system behavior. We then passed that analysis into ChatGPT’s deep research model and allowed it to process the problem for about thirty minutes. Once that analysis came back, we fed it back into the Claude agent. From there the agent generated a complete exploit chain and sabotage method.
Now at this point we had successfully compromised all ten of the services in its entirety and our score point value became devastatingly high.
By noon on the first day we were already 20,000 points ahead of second place.
By the end of the first day the lead had grown to over 40,000 points.
By the morning of the second day we were nearly 200,000 points ahead.
By the end of the competition we finished more than 400,000 points ahead of the next team.
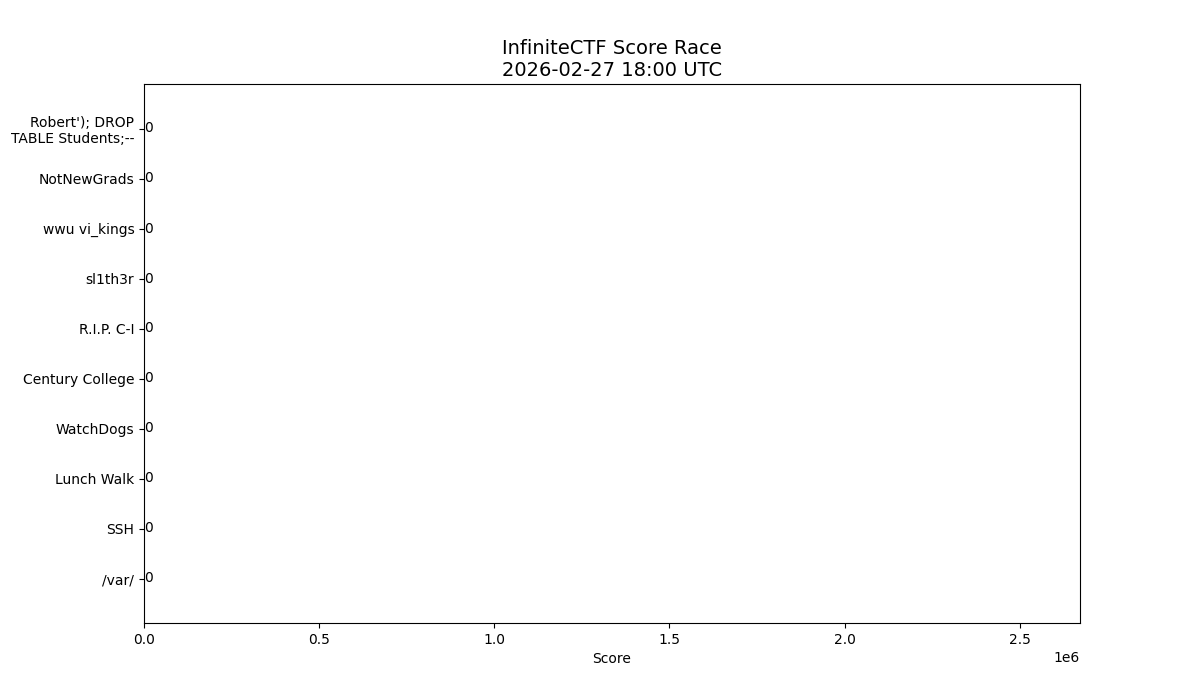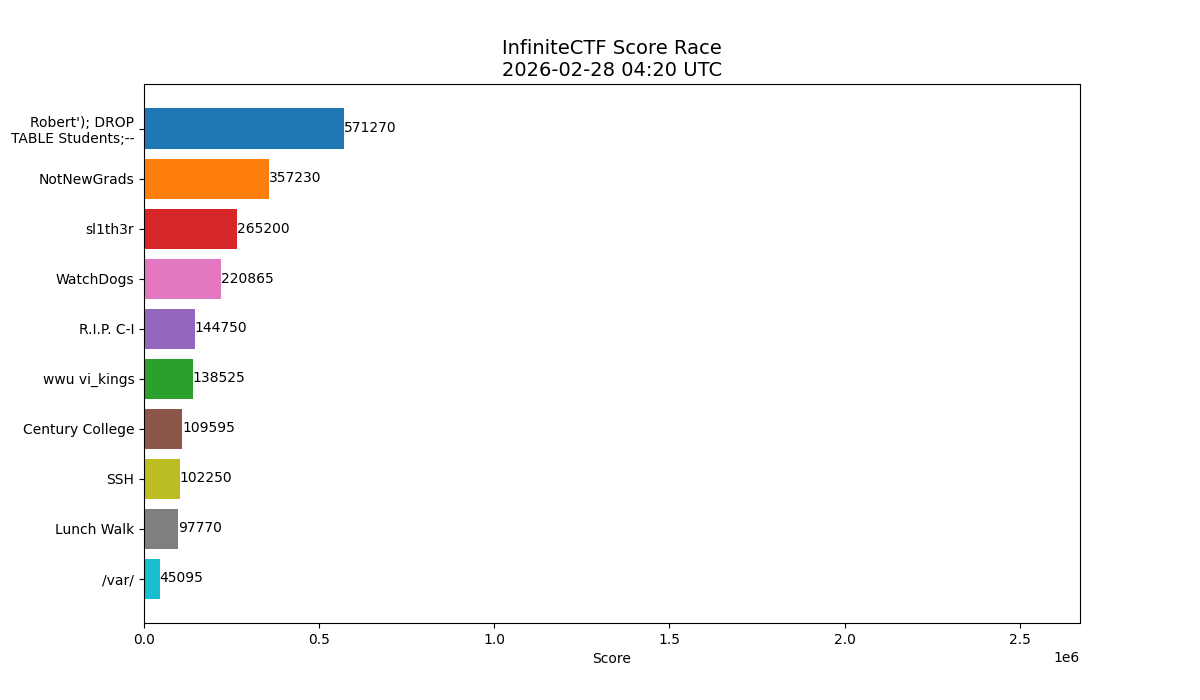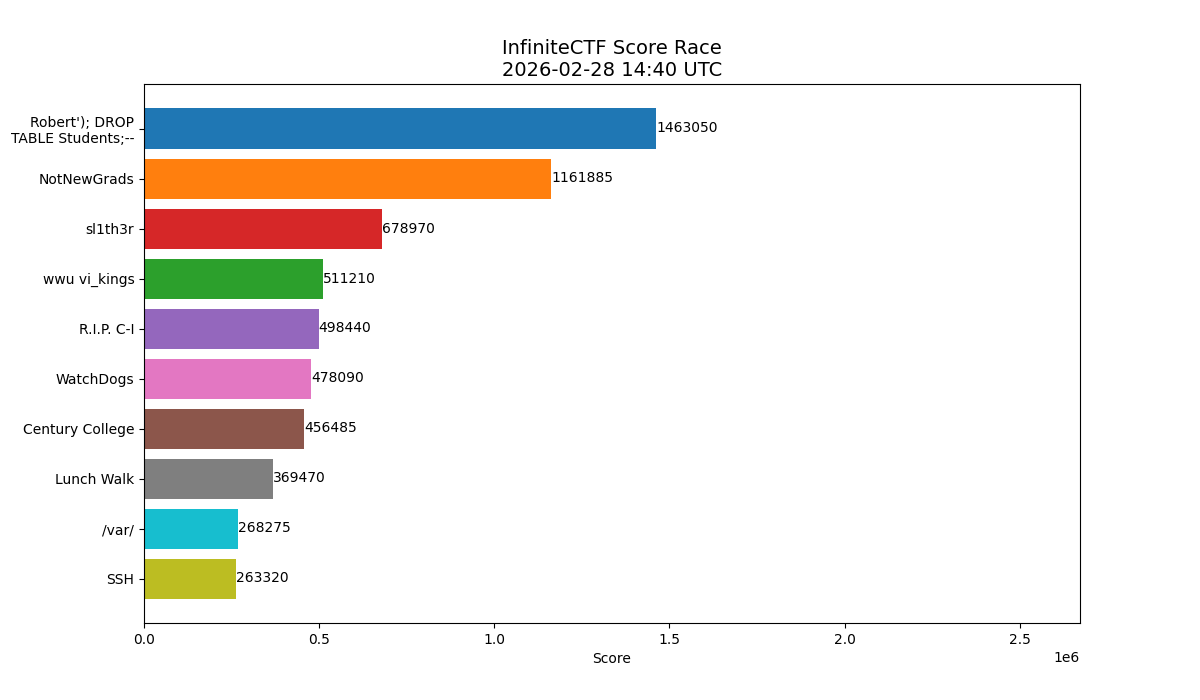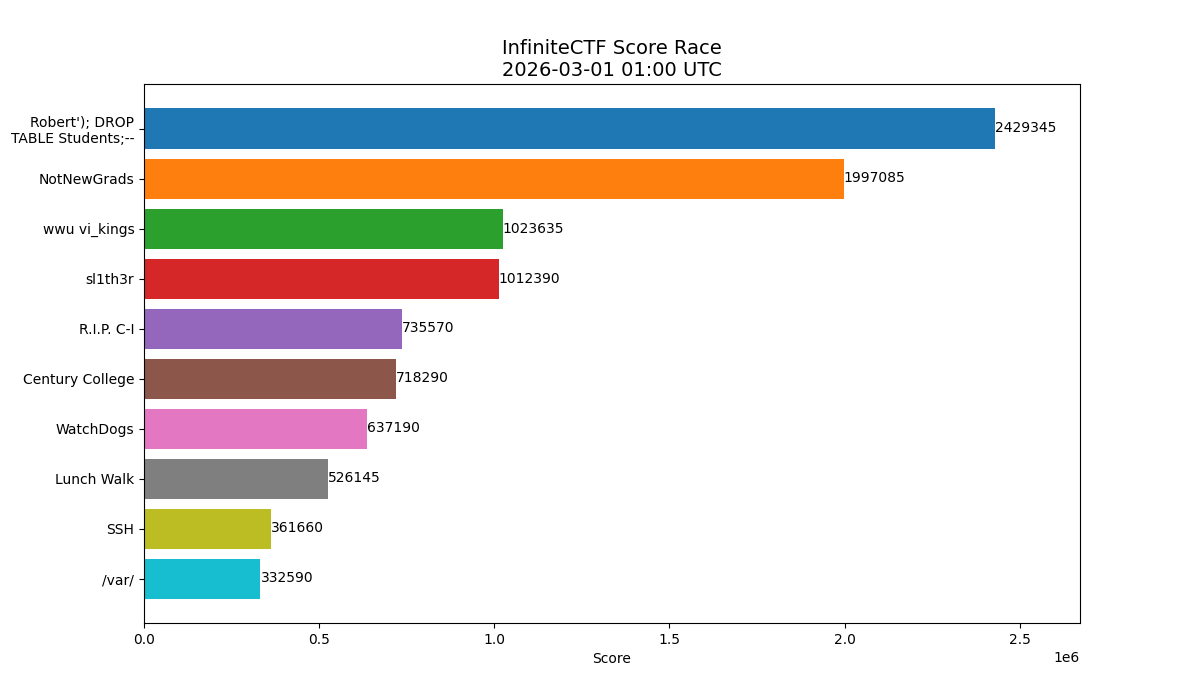
Sabotage as a Strategy

Once a box was solved—meaning the vulnerability was identified, exploited, patched on our system, and exploited against competitors—the agent assigned to that box wasn’t finished.
We reassigned it to another task: sabotage.
In attack-defense CTF competitions, teams analyze logs to understand how opponents are exploiting their services. If you can reconstruct an exploit from the logs, you can patch the vulnerability or use the same exploit yourself.
Traditionally sabotage involves fairly blunt tactics:
- Deleting logs
- Redirecting logs to
/dev/null - Running cron jobs to wipe traces
I’ve used those methods myself in the past. This time the agents did something much more effective.
Once free from exploitation tasks, they began analyzing application and service logs. Using the knowledge they already had about the exploit chain, they generated fake but believable attack traces and injected them into the logs alongside the real entries.
The result was a stream of logs that looked legitimate but described exploit paths that didn’t exist. This completely confused competitors trying to reverse engineer our attacks. It also had another side effect: if competitors fed those logs into their own AI tools for analysis, the AI would frequently reconstruct incorrect exploit chains.
In other words, we were poisoning not only human analysis, but AI analysis as well.
Other sabotage techniques included:
- Randomizing file timestamps to suggest tampering where none occurred
- Rapidly reverting patches applied by competitors
- Injecting or removing variables in application code to intermittently break functionality
- Generating misleading system behavior designed to waste debugging time
None of these techniques were new individually.
What changed was the scale and speed at which they could be executed.
Everyone Was Using AI
We were not the only team using AI. At this point it would be surprising to find teams who aren’t using it. The difference was how we used it. Most teams were using AI as an assistant. We were using orchestrated agents with direct system access and were willing to spend money to remove API rate limits so the agents could run continuously.
That difference turned out to matter.
The End of the Human Middle Layer
You might assume running a system like this required constant oversight. It didn’t. Most of our involvement consisted of occasionally redirecting the agents when they chased a red herring or pursued an exploit chain that clearly wasn’t going to work. These corrections were minor and often based on intuition rather than detailed technical analysis. In many ways we weren’t exploiting systems ourselves anymore.
We were managing AI systems that were doing it for us.
The 24/7 Advantage
Another major factor was the duration of the competition. The B-Sides Seattle CTF runs for two full days, and a lot can happen overnight when teams are asleep.
In the 2025 competition one of my scripts broke in the middle of the night when session tokens expired. Our system stopped submitting flags for about four and a half hours until I woke up and discovered the problem. That cost us a significant number of points. This year the agents were running 24/7. They continuously monitored systems, refreshed tokens, restarted failed processes, and corrected issues immediately. The overnight vulnerability window simply disappeared.
The Learning Problem
There is a major downside to this approach to a CTF.
Traditionally the value of a CTF comes from learning. You encounter unfamiliar vulnerabilities, reverse engineer clever exploits, and walk away with new techniques. This time we didn’t necessarily learn much. We were given vulnerability dossiers explaining how the systems worked, but in many cases we didn’t need to fully understand them. Sometimes the AI exploited the system before we even looked closely at it. This became obvious during conversations with the challenge creators.
Throughout the event several organizers approached our team—the first place team—to ask what we thought of their challenges.
They would ask questions like:
- Did you enjoy the vulnerability?
- What did you think of the exploit chain?
- What did you learn from solving it?
In some cases our honest answer was simply: “We’re not entirely sure what the vulnerability was.” You could see the disappointment immediately. Someone had spent hours designing a clever challenge, and the solution ended up being “the AI figured it out.”
The Question Going Forward
So what does this mean for the future of Capture the Flag competitions?
My first instinct is to say that AI shouldn’t be allowed in CTFs, or that there should at least be a separate category where AI use is prohibited. But the more I think about it, the less realistic that seems. Even if it were enforceable—which it probably isn’t—it also wouldn’t reflect the real world. Attackers are using AI. Defenders are using AI. CTFs are supposed to simulate adversarial environments, and ignoring AI would mean pretending the modern battlefield doesn’t exist.
That may feel better, but it would also mean accepting defeat against adversaries who are willing to use it.
A Historical Analogy

Throughout the competition I kept thinking about an analogy.
At the beginning of World War II, France entered the war with a military structure that still relied heavily on horse cavalry and horse-drawn artillery, mixed with limited modern armor. They expected warfare to resemble World War I. Germany, on the other hand, deployed a fully mechanized army built around tanks and rapid maneuver warfare. The result was devastating.
France had prepared for the previous war, not the one that was actually being fought. In many ways this feels like the moment we are in now with cybersecurity—and with Capture the Flag competitions. We might wish the battlefield still looked like it did ten years ago.
But it doesn’t….
The reality is that we are entering an era where AI agents orchestrate other AI agents, performing reconnaissance, vulnerability discovery, exploit generation, and attack execution at speeds humans cannot match. This is immensely powerful. And it’s a genie we cannot put back into the bottle.
The battlefield has changed. The only question now is how we adapt to it.
Related posts:
 Getting My Certified Ethical Hacker v10 Cert
Getting My Certified Ethical Hacker v10 Cert
 Lab: Breaking Guest WiFi
Lab: Breaking Guest WiFi
 CVE-2021-29255 Vulnerability Disclosure
CVE-2021-29255 Vulnerability Disclosure
 Lab: Exploiting CVE-2021-29255
Lab: Exploiting CVE-2021-29255
 Webserver VHosts Brute-Forcing
Webserver VHosts Brute-Forcing
 RedTeam Tip: Hiding Cronjobs
RedTeam Tip: Hiding Cronjobs
 HTB Walkthrough: Support
HTB Walkthrough: Support
 HTB Dante Skills: Network Tunneling Part 1
HTB Dante Skills: Network Tunneling Part 1